404 Aradığınız Sayfa Bulunamadı

Üzgünüz, aradığınız sayfa bulanamadı.
Ana Sayfaya Dön
İnstagram Şifresiz Takipçi Gönderme ✅ 2026 Ücretsiz Yöntem
İnstagram’da şifre vermeden takipçi kasmak mümkün mü? Takipmax olarak 2026 güncel yöntemleri ve profilinizi güvenle büyütebileceğiniz en etkili yolları.
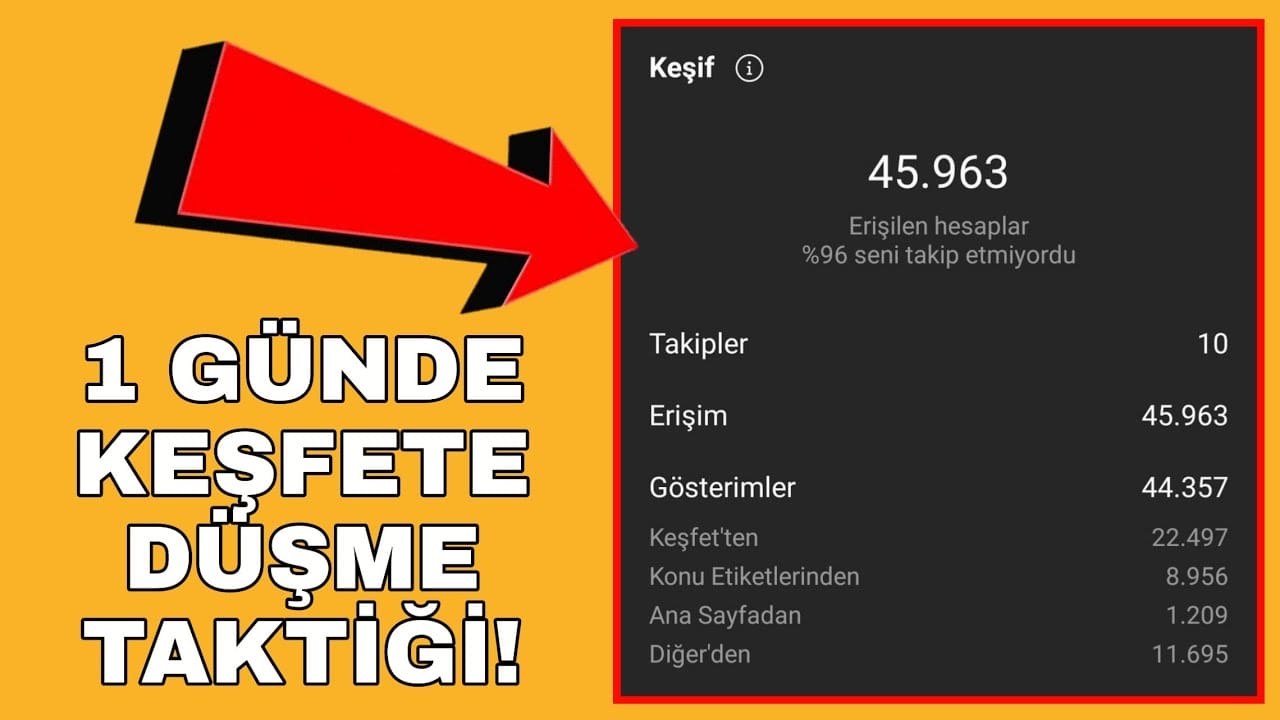
İnstagram'da Keşfete Düşmek ✔️ Denedim ve Sonuç Harika!
İnstagram'da Keşfete Düşmek İçin İşe Yarayan En Etkili Taktikleri Sizin İçin Bi Araya Topladık, Bu Yöntemler İle İnstagram Gönderileriniz Keşfete Düşecek

İnstagram İzlenme Arttırma ✔️ 1.000 İzlenme Bedava
İnstagram Reels Video İzlenme Arttırma ✔️ Hem Ücretsiz Hemde Çok Hızlı Çalışan Bu Servis İle İzlenme Sayılarınızı Arttırın

İnstagram Takipçi Arttırma - Takipçi Kazanma Taktikleri 2025
İnstagram Takipçi Arttırma Yolları - En Etkili Takipçi Kazanma Taktikleri - Şifresiz Takipçi Arttırma Sitesi - Herkese Ücretsiz 1000 Takipçi Bedava

Whatsapp Durumlarına Gizli Bakma - Gizli Durum Görme
Whatsapp Durumlarına Gizlice Görünmeden Bakabileceğini Biliyormusun - Bu Yazıda Whatsapp Durumlarına Gizli Bakmayı Anlattık, Whatsapp Gizli Durum Görme.

Youtube Hesap Çalma Ve Hesap Kırma İşlemleri Nasıl Yapılır?
Bilgisayar korsanlarının en çok yaptığı işlemlerden biri de Youtube hesap çalma işlemidir. Geçtiğimiz günlerde Ruhi Çenet ’in dahi Youtube hesabı çalınmıştı.

İnstagram'da Takibi Bırakanları Görme ve Bulma (2026)
İnstagram'da Seni Takipten Çıkanları Sadece 1 Dakikada Bul - 2026 Beni Kimler Takipten Çıktı

İnstagram Beğeni Hilesi Sorunsuz - Jet Hızında Başlıyor
Ücretsiz İnstagram Beğeni Hilesi - Jet Hızında Başlayan Gerçek Türk Beğeni Hilesi - 2026 Yılının En İyi Beğenileri Burada Seni Bekliyor.

İnstagram 20K Takipçi Satın Al | Güvenilir & Uygun Fiyat
İnstagram 10K, 20K takipçi satın alarak sosyal medyada öne çık! Hızlı teslimat, düşmeyen takipçiler ve güvenilir hizmet seni bekliyor.

İnstagram Uygulamadan Atıyor Sorunu Ve Çözümü 2026
İnstagram Uygulamasına Giriş Yapamıyorum, Geri Atıyor Diyorsanız Bu Yazı Tam Size Göre - Bu Sorunu Nalıl Çözeceğinizi Resimli Bi Şekilde Anlattık.

İnstagram'da Arama Geçmişini Tamemen Silme 2026
Instagram silinen arama geçmişi nasıl bulunur? Instagram uygulamasında, arama geçmişini sildikten sonra arama geçmişini tekrar geri getirmek mümkün değildir.

İnstagram Takipçi Arttırma Hilesi - 5 Dakikada 1.000 Takipçi.!
Ücretsiz Ve Bedava Olan Bu İnstagram Takipçi Arttırma Hilesi İle 5 Dakikada Tam 1.000 Takipçiniz Olacak - Güvenilir Ve Şifresiz Takipçi Arttırma

Tiktok Takipçi Kasma Hilesi - 5 Dakikada 1.000 Takipçi Kazan
Bu Taktik İle 5 Dakikada 1.000 Tiktok Takipçiniz Olacak - Tiktok Takipçi Kasma - Tiktok Takipçi Hilesi - Tiktok Takipçi Kazan

İnstagram Hikaye Görünmüyor Sorunu Ve Çözümü 2026
İnstagram hikayeleri göremiyorum neden - Başkasının hikayesini neden göremiyorum - İnstagram Hiyake Görünmüyor Sorunu Ve Çözümü

TikTok Yaş Sınırı Kaçtır, Tiktok Yaş Sınırı Nasıl Kaldırılır?
Tiktok Yaş Sınırı Değiştirme Yada Kaldırma İşlemi Nasıl Yapılır - Tiktok Yaş Büyütme Ve Doğrulama 2022 - Tiktok Yaş Sınırı Kaç Takipmax'da

İnstagram Ücretsiz Bedava Beğeni Arttırma Hilesi 2025
İnstagram Ücretsiz Ve Otomatik Beğeni Arttırma Hilesi Nasıl Yapılır Yazımıda Anlattık, Bu Yöntemlere Gönderilerinize İnstagram Beğeni Atabilirsiniz

İnstagram Hikaye Paylaşamıyorum Sorunu (2026 Kesin Çözüm)
İnstagram hikaye (story) paylaşma sorunu mu yaşıyorsunuz? 2026 yılına özel güncel çözüm yöntemleri, önbellek temizleme ve teknik ayarlar rehberimizde.

Haberi Olmadan Başkasının İnstagram Mesajlarını Okuma (2026)
Haberi Olmadan Başkasının İnstagram Mesajlarını Okuma Ücretsiz Programsız - Başkasının instagram Mesajlarını Okumak Mümkün Mü?

İnstagram Hesap Çalma Suçu ve Cezaları Şikayet Botu
İnstagram Hesap Çalma Suç Mu - İnstagram Hesap Çalma Şifre Kırma Hackleme Suçu Ve Cezaları Hakkında Bilgiler

İnstagram Neden ve Ne Zaman Satıldı? Ne Zaman Kuruldu 2025
İnstagram Ne Zaman Kuruldu, Ne Zaman Satıldı, Sahibi Kim Tarafından Kuruldu, İşte Tüm Detaylar Yazımızda Takipmax.com

İnstagram Görüntüleme Hilesi ✔️ Profilinizi Hızla Yükseltin!
İnstagram Görüntüleme Hilesi ile takipçi sayınızı artırın, etkileşimi yükseltin ve profilinizi güvenli ve gizli bir şekilde büyütün. Hemen deneyin!

İnstagram Lite Uygulaması Nedir - İnstagram Lite Giriş
İnstagram Lite Uygulaması Nedir, Nasıl Kullanılır, İnstagram Lite Özellikleri Ve İnstagram Lite Uygulamasını Hemen İndirin Yükleyin

Fenomenlerin Kullandığı En İyi Fotoğraf Uygulamaları 2025
Fenomenler Tarafından Sıkça Kullanılan En İyi Fotoğraf Uygulama İsimlerini Bir Araya Topladık, En İyi 5 Fotoğraf Uygulaması

TikTok Bot Basma Hilesi - Hemde Bedava...!
Tiktok Bedava Bot Basma - Tiktok Bot Basma Sitesi Ücretsiz - Tiktok Bot Basma Apk Uygulamasını Ücretsiz İndir

Çalışan TikTok Takipçi Hilesi 100 Çalışıyor Mu?
TikTok Takipçi Hilesi 100 Çalışıyor Mu? Çalışan Tiktok Takipçi Hilesi 2022 - Ücretsiz Bedava Tiktok Takipçi Hilesi

TikTok Gizli Hesabın Beğendiklerini Görme
TikTok Gizli Hesabın Beğendikleri Görünür Mü? TikTok Gizli Hesap Kullanmanın Avantajları ve Dezavantajları Neler? Gizli TİkTok Hesabın Beğendiklerini Görmek.

TikTok Hesabına Bakanları Görme Yöntemi
TikTok Profile Bakanlar Görünür Mü? TikTok Profile Bakınca Hesap Sahibine Bildirim Gider Mi? TikTok Profilime Bakanları Görme Özelliğini Nasıl Açılır?

TikTok Takipçi Nasıl Satın Alınır - Tiktok Takipçi Satın Alma
TikTok Takipçi Hilesi Nedir? TikTok Takipçi Hilesi Nasıl Yapılır? TikTok Takipçi Hilesi Hesaba Zarar Verir Mi? Güvenilir TikTok Takipçi Nasıl Satın Alınır?

İnstagram 50 Türk Beğeni Satın Al - Gerçek Türk Beğeni
İnstagram Beğeni Nasıl Satın Alınır? İnstagram 50 Beğeni Nerelerden Satın Alınır? İnstagram Beğeni Arttırma Avantajları Nelerdir? Etkileşim Arttırma Yolları.

İnstagram 5000 Takipçi Hilesi ✔️ Hemen Takipçi Gönder ✔️
İnstagram 5000 takipçi hilesi ile takipçi sayınızı arttırın ve hesabınızı hızla büyütün. Hızlı ve güvenli takipçi kazanma yöntemlerini keşfedin.

Takipten Çıkmayan Takipçi Satın Almak
Takipten Çıkmayan Takipçi Nedir? Düşmeyen Takipçi Nasıl Satın Alınır? Instagram Organik Takipçi Kasma Yolları Neler? Düşmeyen Takipçi Satın Almak Mantıklı Mı?

En İyi İnstagram Takipçi Hilesi Siteleri Listesi
İnstagram Takipçi Hilesi'mi Lazım Sizler İçin En İyi Takipçi Hilesi Siteleri Ve Uygulamalarını Araştırdık, İşte Detaylar.

En Şekil İnstagram Kullanıcı Adı Önerileri 2025
Sizi çok mutlu edecek instagram kullanıcı isimleri - Şekil, Cool, Fake, Priv Tüm Kullanıcı adları burada

Instagram Video İzlenme Hilesi - Herkese 10000 İzlenme Ücretsiz
Instagram İzlenme Sayısı Nasıl Arttırılır? Instagram Şifresiz İzlenme Arttırma Nasıl Yapılır? Instagram Reels İzlenme Sayısı Arttırma Yöntemleri Nelerdir?

İnstagram Takipçi Arttırma Uygulaması ⭐ 2025
İnstagram Takipçi Arttırma Yöntemlerini Sizin İçin En İyi Şekilde Anlattık, Bu Taktiklerle Hesabınızı Büyütün.

TikTok Neden Çöker, Nasıl Düzeltilir?
TikTok Uygulaması Çökme Nedenleri Neler? TikTok Uygulaması Çökerse Ne Yapılmalı? TİkTok Uygulaması Güncellenirse Çökme Sorunu Düzelir Mi? TikTok Erişim Sorunu.

İnstagram Bot Takipçi ✔️ Ücretsiz Bot Takipçi Basalım
İnstagram Bot Takipçi Basma İşlemini Ücretsiz Olarak Yapabileceğinizi Biliyormuydunuz, Üstelik 1000 Türk Takipçi Bedava Hemen Deneyebilirsin.

İnstagram Takipçi Kasma Yöntemleri - Takipçi Kasma Siteleri
İnstagram takipçi kasma yöntemleriyle hesabını ücretsiz ve güvenli şekilde büyüt! Şifresiz ve organik takipçi kazanmanın yollarını hemen keşfet

İnstagram Bot Takipçi Satın Alma (2025) Hızlı Güvenilir
İnstagram'da takipçi sayınızı artırmak için güvenilir bot takipçi satın alma yöntemleri ve avantajları hakkında bilgi edinin.

Tiktok Gerçek Beğeni Hilesi Ücretsiz
İhtiyacınız Olan Gerçek Tiktok Beğeni Hilesi Burada Sizi Bekliyor, Ücretsiz Ve Bedava Olan Bu Servisi Tüm Ziyaretçilerimiz Kullanabilir.

İnstagram Şifresiz Video Reels Görüntülenme Hilesi 2025
İnstagram Görüntülenme Hilesi Nasıl Yapılır - İnstagram Video Görüntüleme Hilesi Şifresiz - İnstagram Görüntülenme Sayısı Nasıl Artar

Instagram Takipçi Gizleme ✔️ Takipçi Sayısı Nasıl Gizlenir
İnstagram Takipçi Gizleme Özelliği Nasıl Kullanılır, Yazımızda Tüm Detayları İle Anlatıyoruz, Artık Sizde Takipçi Sayısını Gizleyebilirsiniz.

İnstagram Gerçek Takipçi Satın Al - Ucuz Ve Güvenilir
İnstagram Gerçek Takipçi Satın Al - Ucuz Ve Güvenilir - Gerçek Türk Takipçi Satın AL - Düşmeyen Organik Türk Takipçi Paketleri Satın AL

İnstagram Öne Çıkanlar Gözükmüyor ✔️ Çözüm Burada
İnstagram Öne Çıkanlar Neden Gözükmüyor? Bu Sorunu Nasıl Çözebilirsiniz? Tüm Detayları Ve Sorunun Çözümünü Anlatıyoruz, Tek Tıkla Bu Sorundan Kurtulun.

İnstagram Bot Takipçi Atma ✔️ Ücretsiz Hızlı Ve Kolay
İnstagram bot takipçi atma işlemi, hesabınızın takipçi sayısını hızlı bir şekilde artırmak için kullanılan bir yöntemdir ✔️ İnstagram Bot Takipçi Hilesi

İnstagram Organik Takipçi Hilesi ✔️ 1000 Takipçi Bedava
İnstagram organik takipçi hilesi, hesabınızın organik olarak büyümesine yardımcı olacak stratejiler ve taktiklerdir.

Ücretsiz İnstagram Takipçi Hilesi ✔️ 1000 Takipçi Bedava
Hem Ücretsiz Hemde Bedava İnstagram 1000 Takipçi Hilesi İstermisin? Cevabın Evet İse Hemen Sitemizi Ziyaret Edin Ve 1000 Takipçi Kazanın

İnstagram Takipçi Servisi ✔️ Hızlı ve Organik Büyüme Şansı!
Etkileyici içerikleriniz için gerçek ve aktif takipçilere ulaşın! Güvenilir ve hızlı Instagram takipçi servisi ile sosyal medyada markanızın gücünü artırın.

SEO Hizmetiyle Dijital Dünyada Başarıya Ulaşın
HTekin dijital web ajansı olarak, markanızı öne çıkarmak ve potansiyel müşterilere ulaşmanızı sağlamak için SEO hizmeti ve danışmanlığı sunuyoruz.

TikTok Bot Basma ✔️ 1'dakikada 1000 Türk Takipçi Bas
Sadece 1'dakikada Tikrok Hesabınıza 1000 Adet Bot Takipçi Gönderebilirsiniz, Tiktok Bot Takipçi Basma İşlemi Tamamen Ücretsizdir.

Fake Hesabın Kime Ait Olduğunu Bulma ✔️ Hemen Bul
İnstagram'da Sizi Rahatsız Eden Fake Hesabın Kime Ait Olduğunu Bulmanıza Yardımcı Oluyoruz ✔️ Fake Hesabın Kime Ait Olduğunu Hemen Bul.

İnstagram Güvenilir Takipçi Satın Alma
İnstagram Güvenilir Takipçi Satın Al - En Güvenilir Takipçi Satın Alma Siteleri Hangisi, Sizin İçin Güvenilir Siteleri Araştırdık

İnstagram 10000 Takipçi Hilesi ✔️ Profilinizi Güçlendirin ✔️
İnstagram 10000 Takipçi Hilesi ✔️ İnstagram 10000 Takipçi Kaç TL ✔️ İnstagram 10000 Takipçi Satın AL ✔️ İnstagram 10K Takipçi Hilesi

Uygun İnstagram Takipçi Satın Al ✔️ En Ucuz Fiyat
En Uygun İnstagram Takipçi Satın Al ✔️ Gerçek ve Aktif Takipçilerle Sosyal Medya Etkileşiminizi Artırın!

Tiktok 1000 Takipçi Satın Al ✔️ En Ucuz Fiyat Garantisi ❤️
Tiktok 1000 Takipçi Satın Al ✔️ Güvenilir Ve Ucuz Takipçi İsteyenler İçin En Uygun Tiktok Takipçi Satın Alma Sitesi Takipmax'a Gelin ❤️

İnstagram Beğeni Servisi ❤️ 5'dakikada 1000 Beğeni
İnstagram Beğeni Servisi Hizmetimizi Kullanarak İnstagram Hesabınıza Ücretsiz Olarak 1000 Adet Gerçek Türk Beğeni Gönderebilirsiniz

Tiktok Jeton Siteleri ✔️ Jeton Satan En İyi Siteler
Tiktok Ucuz Jeton Alma Sitelerini Sizin İçin Araçtırdık, Tiktok Jeton Yükleme Siteleleri İle Hesabınıza Güvenli Bir Şekilde Tiktok Jeton Satın Alabilirsiniz.

İnstagram Takipçi Çoğaltma ❤️ 2'dakikada 1000 Takipçi
İnstagram Takipçi Çoğaltma Hilesi İle Hızla Yükselmeye Hazırmısın, Bedavaya İnstagram Takipçi Sayınızı Çoğaltıyoruz.

İnstagram 20000 Takipçi Hilesi ❤️ 5'dakikada 20K Takipçi
İnstagram 20.000 Takipçi Hilesi - Instagram’da Takipçi Sayınızı 20.000’e Çıkarmak İçin 5 Basit Adım | İnstagram’da takipçi sayınızı artırmak hemen dene...

İnstagram 30K Takipçi Hilesi ✔️ Tek Tıkla 30K Takipçi
Yanlış Duymadınız İnstagram'da Tek Tıkla 30K Takipçi Kazana Bilirsiniz ✔️ 30K İnstagram Takipçi İçin Hemen Takipmax'a Gel Ve Takipçilerini Al

İnstagram Sahte Takipçi ✔️ Sahte Fake Takipçi Bulma
İnstagram'da Sahte Takipçi Nasıl Yapılır ✔️ Sahte Takipçi Bulma Ve Sahte Bot Takipçiler Nasıl Bulunur Bu Yazımızda Anlatıyoruz.

İnstagram Takipçi Hilesi 2026 ✔️ Ücretsiz ve Etkili Yöntem
2026 için en az bilinen İnstagram takipçi hilelerini açığa çıkarıyoruz. Şifresiz ve ücretsiz bu yöntemlerle takipçi sayınızı nasıl artırabileceğinizi öğrenin.

Bedava İnstagram Takipçi Hilesi ✔️ Türk Gerçek Takipçi
Hemen Sitemize Giriş Yaparak Tam 1000 Adet Bedava İnstagram Takipçi Hilesi Kazanabilirsin, Beklemek Yok Ücret Ödemek Yok

İnstagram 500 Takipçi Hilesi ✔️ %50 İndirimle Hemen Satın Al
İnstagram 500 Takipçi Hilesi İle Sosyal Medyada Görünürlüğünüzü artırın. İnstagram'da 500 Takipçi Hilesini Hemen Keşfedin!

İnstagram Takipçi Gönder ✔️ 2'Dakikada 1000 Takipçi
İnstagram Yada Tiktok Hesabınıza Takipçimi Lazım, O Halde Hemen 1000 Takipçiyi Ücretsiz Bir Şekilde İnstagram Hesabınına Gönder.

Bedava İnstagram Takipçi Hilesi ✔️ Şimdi 1000 Takipçi Hediye
Sadece 5 Dakikanızı Ayırarak Bizden Bedava İnstagram Takipçi Hilesi Kazanabilirsiniz, Şifre Girmeden Hemen Türk Takipçilerinizi Alın

İnstagram Bot Basma ✔️ Ücretsiz Bot Takipçi Basma
İnstagram Bot Basma Servisini Kullarak İnstagram Hesabınıza Bot Takipçi Atabilirsiniz, Bot Takipçi Hizmeti Ücretsizdir Ve Herkes Kullanabilir.

İnstagram Takipçi Artırma - 10.000 Takipçiye Ulaşma Hikayesi
Takı tasarımcısı Ayşe, Instagram'da 100.000 takipçiye ulaştı! Etkili sosyal medya stratejilerini öğrenin ve siz de hesabınızı büyütün

Takipçi Hilesi Yap ve Etkileşim Kazan – %100 İşe Yarıyor
Takipçi hilesi yaparak hem takipçi sayımı hem de etkileşim oranlarımı artırdım. Güvenilir araçlar ve ipuçları bu rehberde.

Parasız Instagram Takipçi Hilesi 2025 | Şifresiz ve Güvenli
İnstagram’da şifresiz ve ücretsiz takipçi hilesi mümkün mü? Güvenli ve risksiz yöntemlerle takipçi artırmanın yollarını şimdi öğrenin!

İnstagram 10K Takipçi Hilesi ✔️ Ücretsiz Jet Hızında
İnstagram’da 10K takipçiye ulaşmak mı istiyorsun? 2026’in en güncel takipçi hilesi yöntemlerini keşfet! Şifresiz, bedava ve güvenli yollar burada.

İnstagram Takip Engeli Kaldırma ✔️ Kesin Çözüm Yöntemi
İnstagram’da takip engeli sorunuyla mı karşılaştınız? Engelin süresi, nasıl kalkacağı ve önleme yöntemlerini detaylıca açıkladık.

İnstagram Aktiflik Kapatma ✔️ Tek Tıkla Kapatalım
İnstagram’da Aktiflik Kapatma Nasıl Yapılır? Hikaye ve Mesajlarda Görünürlüğünüzü Kapatmanın En Pratik Yolunu Öğrenin.

YouTube Bot Basma – 1000 Abone Ücretsiz! (2025)
Hiçbir ücret ödemeden YouTube kanalına 1000 abone eklemek ister misin? Bot sistemleriyle ilgili detaylı rehber seni bekliyor.

İnstagram Beğeni Kasma Hilesi Türk – Garantili
İnstagram beğeni kasma yöntemleri ile gönderilerinize ücretsiz ve şifresiz beğeni kazanın. Türk kullanıcılarla güvenli, hızlı ve doğal etkileşim için hemen keşfedin!

İnstagram Beğeni Hilesi Şifresiz (2025) – Ücretsiz ve Güvenli
2025’in en güncel şifresiz İnstagram beğeni hilesi yöntemlerini keşfedin. Hesap şifresi paylaşmadan güvenli şekilde beğeni kazanmanın yolları burada!

İnstagram Ücretsiz Takipçi ✔️ 1000 Takipçi Bedava
İnstagram takipçi hilesi ücretsiz mi? Risklerini öğrenin! Botlardan kaçınarak hesabınızı organik ve doğru stratejilerle ücretsiz büyütün.

Tiktok Takipçi Kasma ✔️ 2'dakikada 1000 Takipçi
Sadece 2'dakikanızı Ayrırarak Tiktok Hesabınıza 1000 Türk Ve Gerçek Takipçi Kasabilirsiniz, Bu Hizmet Ücretsiz Olum Tiktok Hesabı Olan Herkes Kullanabilir.

İnstagram Mesaj Gitmiyor ✔️ Sorunu Ve Çözümü (2026)
İnstagram'da Mesaj Gitmiyor Sorunu Yaşıyorsanız Size Önerdiğimiz Önerileri Uygulayın Ve Bu Hatadan 2'dakikada Kurtulun.

İnstagram Görüntülenme Hilesi - 5000 İzlenme Bedava
İnstagram Hesabı Olan Herkese Tam 5000 Görüntülenme Hilesi Bedava, Tek Yapman Gereken Reels Video Linkinizi Girin Ve Gönder Butonuna Dokunun.
